I found a recent paper that also looks at how the BSD code base has evolved, but from a very different perspective compared to my code-size investigation.
The paper "The Evolution of C Programming Practices: A Study of the Unix Operating System 1973–2015" investigates coding style, and tests seven hypotheses by looking at metrics (line length, number of
The paper "The Evolution of C Programming Practices: A Study of the Unix Operating System 1973–2015" investigates coding style, and tests seven hypotheses by looking at metrics (line length, number of
volatile in the source code, etc.) in 66 releases of Unix from 1973 to 2014. The hypotheses are- Programming practices reflect technology affordances (e.g. developers may be more liberal with screen space when using high resolution displays)
- Modularity increases with code size
- New language features are increasingly used to saturation point
- Programmers trust the compiler for register allocation
- Code formatting practices converge to a common standard
- Software complexity evolution follows self correction feedback mechanisms
- Code readability increases
There are several things that annoys me with this paper...
Source code change over time
The earliest source code releases in the study are the "Research systems" from Bell Laboratories, which are followed by Bell-32V, different BSD versions from University of California, BSD386, and FreeBSD. Of these, it is only FreeBSD that continues after 1995, so the early range 1973–1995 consists of multiple variants of the OS developed by different groups in parallel, while the data 1996–2014 consists of FreeBSD only. This may affect the interpretation of the data...
Consider for example this plot from the paper, showing the mean comment size
Consider for example this plot from the paper, showing the mean comment size
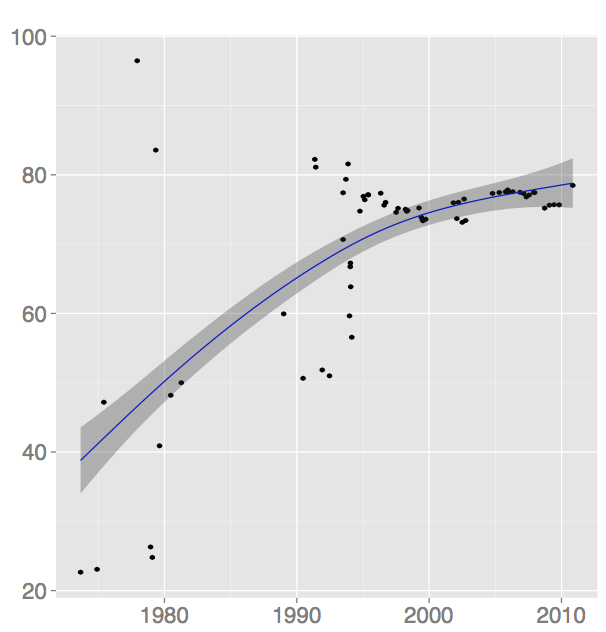 |
| CMCHAR — mean comment size |
The first part of the plot that consists of multiple variants of the OS have points all over the place, while the second part is FreeBSD only, and is rather constant. Several of the metrics have this kind of distribution, and I am not convinced that the data can be interpreted as evolution (rather than different projects have different coding style), or that fitting a cubic spline to the data have much value for this data set.
Language change over time
Some of the metrics are for new functionality in the C language, and are used for testing hypothesis 3 — "new language features are increasingly used
to saturation point". But that hypothesis is in some sense obviously true for most of the metrics. For example, K&R C did not have
So the metrics mostly measure that the projects switched from K&R C to standardized C, and most of the graphs looks like
volatile, but C90 requires volatile in order to prevent the compiler from optimizing away memory accesses to memory mapped hardware registers. Furthermore, there are only a finite number of places where it makes sense to use it, so it obviously saturates.So the metrics mostly measure that the projects switched from K&R C to standardized C, and most of the graphs looks like
 |
DVOL — volatile keyword density |
That is, first no usage, then the feature is introduced in all relevant places when the project updates the compiler.
One other issue here is that the header files are excluded in the calculated metrics. I do not think it affects the result of the conclusion (as it is a rather weak statement anyway), but I have often seen things like
#define HW_REG volatile unsigned int
being defined in header files, and such usages are not included in the data (and this skews the data in the discussion of
restrict, where the code uses it as __restrict in order to be able to define it in a suitable way for old compilers that do not handle restrict).Release dates
The data points for the releases have somewhat random dates. One issue is that the paper use each release's mean file date (the average of the files' last modification time) instead of the release date (that is why the graphs stop at November 2010, even though FreeBSD 10 was released in 2014). The idea is that this better reflects the age of the code base, but this has the effect of compressing some of the data points (especially the clustering around 1993-1994), and it makes the spline fitting even more suspect.One other problem is that the original data used by the researchers seems to have incorrect timestamps. For example, 4.3BSD Net/1 was released in 1989, but is listed as 1993-12-25 in the paper. The same is true for at least the Net/2 release too, which was released in 1991, but the paper list it as 1993-07-02.